独バイエルが開発した創薬支援プラットフォーム「PRINCE」は、大規模言語モデル(LLM)を実務で安定稼働させるための設計指針を提示している。これは、複雑な非臨床試験データを扱う現場で、AIを単なる検索ツールから自律的な研究アシスタントへと昇華させた技術的アプローチである。
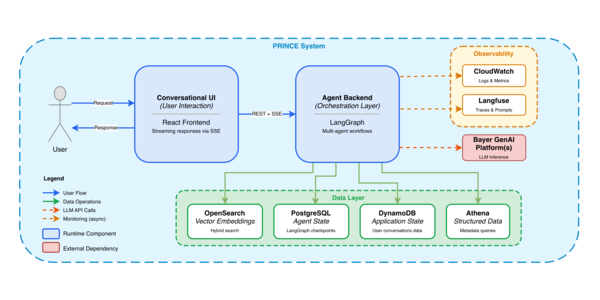
バイエルとThoughtworksの技術報告によれば、PRINCEはLLMの予測不可能性を前提とし、モデル単体の性能追求に留まらないアプローチを採用している。その核となるのは、「コンテキストエンジニアリング」と「ハーネスエンジニアリング」という二つの概念である。研究、推論、執筆といった専門エージェント間で情報を最適化して受け渡し、さらにオーケストレーションや検証、エラー回復、可観測性といった堅牢な基盤構築によって、システム全体の信頼性を担保する手法だ。
創薬プロセスにおける膨大な非臨床試験データの解析は、製薬業界が長年抱えてきた課題である。従来のキーワード検索では、専門用語の多義性や文脈の欠如により、必要な情報にたどり着くことが困難であった。また、医薬品開発は厳格な規制対応が求められるため、単なる情報検索ではなく、その情報の信頼性や説明責任の確保が不可欠である。この課題に対し、PRINCEはエージェント型RAGとText-to-SQLを組み合わせ、自然言語による対話型システムへと進化を遂げている。
PRINCEの信頼性を支える具体的な技術構成は、AIの回答を盲信するのではなく、検証エージェントによるデータ妥当性の確認や、人間が介在するループ(Human-in-the-loop)を組み込む点にある。これにより、生成された情報の透明性と説明責任が確保される。米国食品医薬品局(FDA)のガイダンス草案でも示唆されている通り、高リスクシステムに求められる透明性や人間の監督といった要件に対し、AIの出力を人間が検証するプロセスをシステムに統合することで対応している。
AIの回答が常に正しいとは限らないという前提に立ち、検証プロセスを組み込むPRINCEの設計思想は、高い正確性が求められる他の専門領域にも大きな示唆を与える。法務や金融、医療診断といった分野では、AIの「幻覚」が重大なリスクとなり得る。一般的なLLMが薬物相互作用チェックで54%しかスコアを獲得できなかったという研究結果も報告されており、AIの予測不可能性を前提とした堅実なエンジニアリングアプローチは、これらの業界におけるAIアプリケーション開発の成功率に直結する知見と考えられる。
PRINCEのようなマルチエージェント構成は、システムの複雑化に伴い、推論ミスの特定やデバッグが困難になるリスクを孕んでいる。AIの回答精度を客観的かつ継続的に評価するための具体的な指標(メトリクス)の確立や、エージェント間の情報伝達におけるレイテンシが実務上のユーザー体験に与える影響も考慮すべき課題である。今後は、システムが複雑化する中で、監視体制や評価指標がどのように拡張・標準化されていくのか、その動向を注視する必要がある。